Fog computing is a decentralized computing infrastructure in which data, compute, storage and applications are located somewhere between the data source and the cloud. Like edge computing, fog computing brings the advantages and power of the cloud closer to where data is created and acted upon. Many people use the terms fog computing and edge computing interchangeably because both involve bringing intelligence and processing closer to where the data is created. This is often done to improve efficiency, though it might also be done for security and compliance reasons.
The fog metaphor comes from the meteorological term for a cloud close to the ground, just as fog concentrates on the edge of the network. The term is often associated with Cisco; the company's product line manager, Ginny Nichols, is believed to have coined the term. Cisco Fog Computing is a registered name; fog computing is open to the community at large.

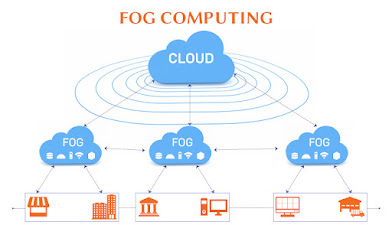
Types of Fog Computing
- Device-level Fog Computing: Device-level fog computing utilizes low-power technology, including sensors, switches, and routers. It can be used to collect data from these devices and upload it to the cloud for analysis.
- Edge-level Fog Computing: Edge-level fog computing utilizes network-connected servers or appliances. These devices can be used to process data before it is uploaded to the cloud.
- Gateway-level Fog Computing: Fog computing at the gateway level uses devices to connect the edge to the cloud. These devices can be used to control traffic and send only relevant data to the cloud.
- Cloud-level Fog Computing: Cloud-level fog computing uses cloud-based servers or appliances. These devices can be used to process data before it is sent to end users.
Basic Components of Fog Computing
There are multiple ways of implementing a fog computing system. The common components across these architectures are explained below.
1. Physical & virtual nodes (end devices)
End devices serve as the points of contact to the real world, be it application servers, edge routers, end devices such as mobile phones and smartwatches, or sensors. These devices are data generators and can span a large spectrum of technology. This means they may have varying storage and processing capacities and different underlying software and hardware.
2. Fog nodes
Fog nodes are independent devices that pick up the generated information. Fog nodes fall under three categories: fog devices, fog servers, and gateways. These devices store necessary data while fog servers also compute this data to decide the course of action. Fog devices are usually linked to fog servers. Fog gateways redirect the information between the various fog devices and servers. This layer is important because it governs the speed of processing and the flow of information. Setting up fog nodes requires knowledge of varied hardware configurations, the devices they directly control, and network connectivity.
3. Monitoring services
Monitoring services usually include application programming interfaces (APIs) that keep track of the system’s performance and resource availability. Monitoring systems ensure that all end devices and fog nodes are up and communication isn’t stalled. Sometimes, waiting for a node to free up may be more expensive than hitting the cloud server. The monitor takes care of such scenarios. Monitors can be used to audit the current system and predict future resource requirements based on usage.
4. Data processors
Data processors are programs that run on fog nodes. They filter, trim, and sometimes even reconstruct faulty data that flows from end devices. Data processors are in charge of deciding what to do with the data — whether it should be stored locally on a fog server or sent for long-term storage in the cloud. Information from varied sources is homogenized for easy transportation and communication by these processors.
This is done by exposing a uniform and programmable interface to the other components in the system. Some processors are intelligent enough to fill the information based on historical data if one or more sensors fail. This prevents any kind of application failure.
5. Resource manager
Fog computing consists of independent nodes that must work in a synchronized manner. The resource manager allocates and deallocates resources to various nodes and schedules data transfer between nodes and the cloud. It also takes care of data backup, ensuring zero data loss.
Since fog components take up some of the SLA commitments of the cloud, high availability is a must. The resource manager works with the monitor to determine when and where the demand is high. This ensures that there is no redundancy of data as well as fog servers.
6. Security tools
Since fog components directly interact with raw data sources, security must be built into the system even at the ground level. Encryption is a must since all communication tends to happen over wireless networks. End users directly ask the fog nodes for data in some cases. As such, user and access management is part of the security efforts in fog computing.
7. Applications
Applications provide actual services to end-users. They use the data provided by the fog computing system to provide quality service while ensuring cost-effectiveness. It is important to note that these components must be governed by an abstraction layer that exposes a common interface and a common set of protocols for communication. This is usually achieved using web services such as APIs.
Benefits of fog computing
Like any other technology, fog computing has its pros and cons. Some of the advantages to fog computing include the following:
- Bandwidth conservation. Fog computing reduces the volume of data that is sent to the cloud, thereby reducing bandwidth consumption and related costs.
- Improved response time. Because the initial data processing occurs near the data, latency is reduced, and overall responsiveness is improved. The goal is to provide millisecond-level responsiveness, enabling data to be processed in near-real time.
- Network-agnostic. Although fog computing generally places compute resources at the LAN level as opposed to the device level, which is the case with edge computing, the network could be considered part of the fog computing architecture. At the same time, though, fog computing is network-agnostic in the sense that the network can be wired, Wi-Fi or even 5G.
Disadvantages of fog computing
Of course, fog computing also has its disadvantages, some of which include the following:
- Physical location. Because fog computing is tied to a physical location, it undermines some of the "anytime/anywhere" benefits associated with cloud computing.
- Potential security issues. Under the right circumstances, fog computing can be subject to security issues, such as Internet Protocol (IP) address spoofing or man in the middle (MitM) attacks.
- Startup costs. Fog computing is a solution that utilizes both edge and cloud resources, which means that there are associated hardware costs.
- Ambiguous concept. Even though fog computing has been around for several years, there is still some ambiguity around the definition of fog computing with various vendors defining fog computing differently.




No comments:
Post a Comment